
问题陈述
异常值问题:
- 大规模数据集中存在不可预期的异常值:难以发现,但可能对预测结果产生负面影响。
- 数据采集过程中的“摄像头闯入”:连续采集使得异常值移除更加困难。
- 人为引入的多样性:人类无法精确控制异常值插入的程度,从而影响预测准确性。
当前 Teachable Machine 的设计问题:
- Teachable Machine 将所有输入均视为训练数据,缺乏识别异常值的能力。
- 预测细节隐藏过深,不利于缺乏机器学习背景的用户理解。
设计启示:
- 通过引入 human-in-the-loop 方法,用户可以识别异常值。
- 以简化的预测细节并配合恰当解释,可帮助用户理解异常值对模型的潜在影响。
研究目标
我们如何提供反馈,使用户理解异常值如何影响模型预测准确率,从而提供更高质量的训练样本?
- (问题1)界面如何提醒用户其可能在训练数据中无意引入了异常值?
- (问题2)界面如何有效引导用户对 Teachable Machine 算法给出的异常值建议进行筛选?
原型设计
初始方案 01:人工监督分类
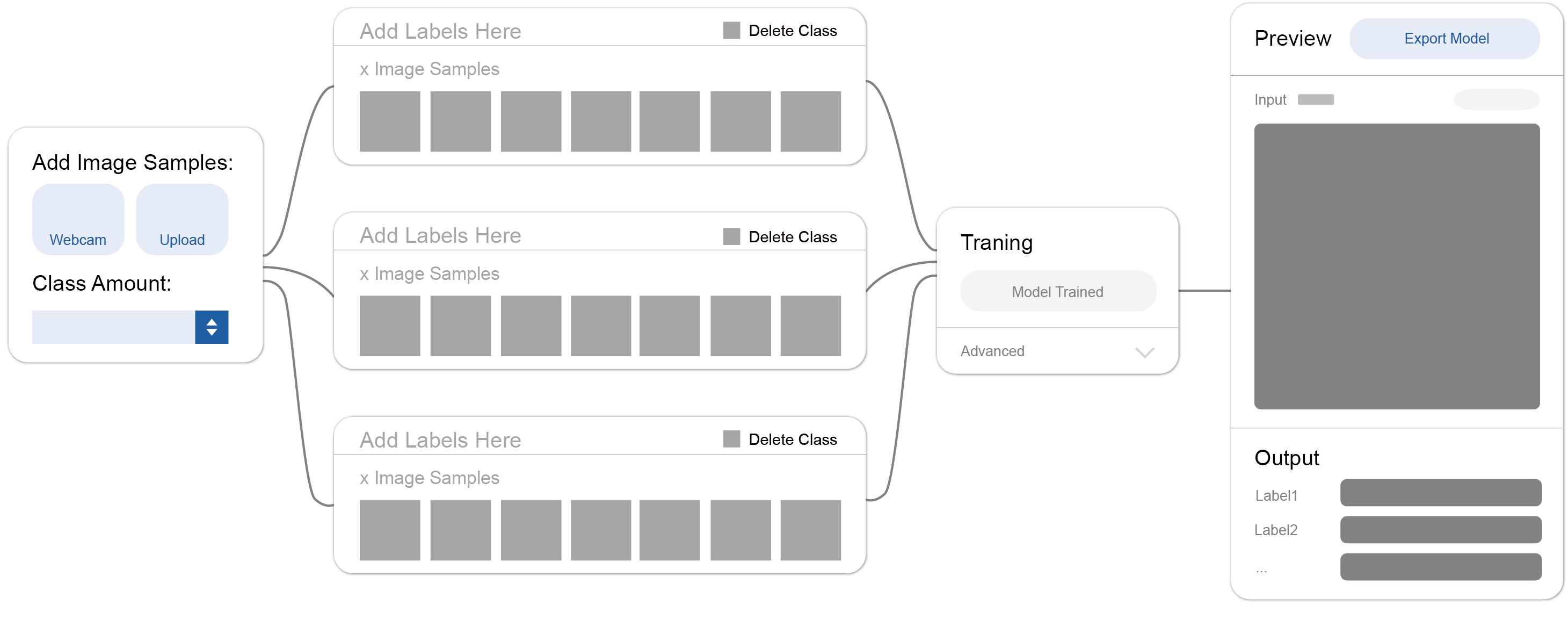
初始方案 01:人工监督分类
初始方案 02:被动式异常值识别与纠正
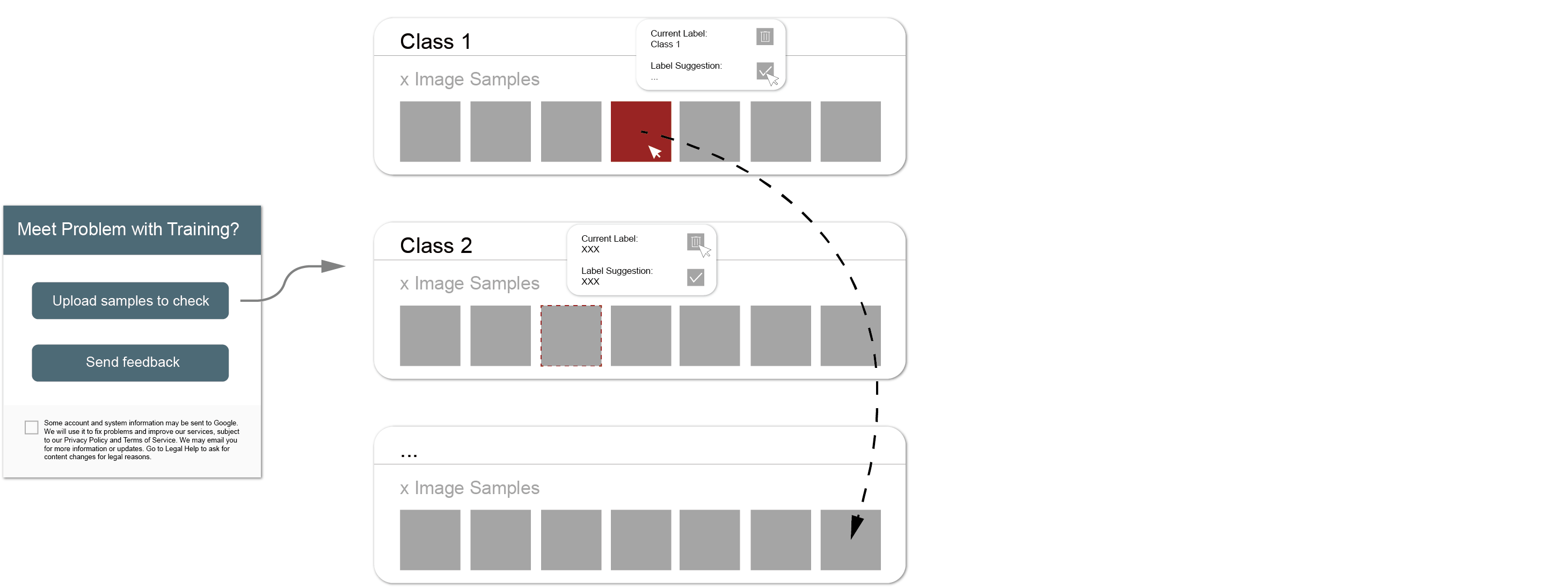
初始方案 02:被动式异常值识别与纠正
最终方案:“提醒”界面与“异常值过滤”界面
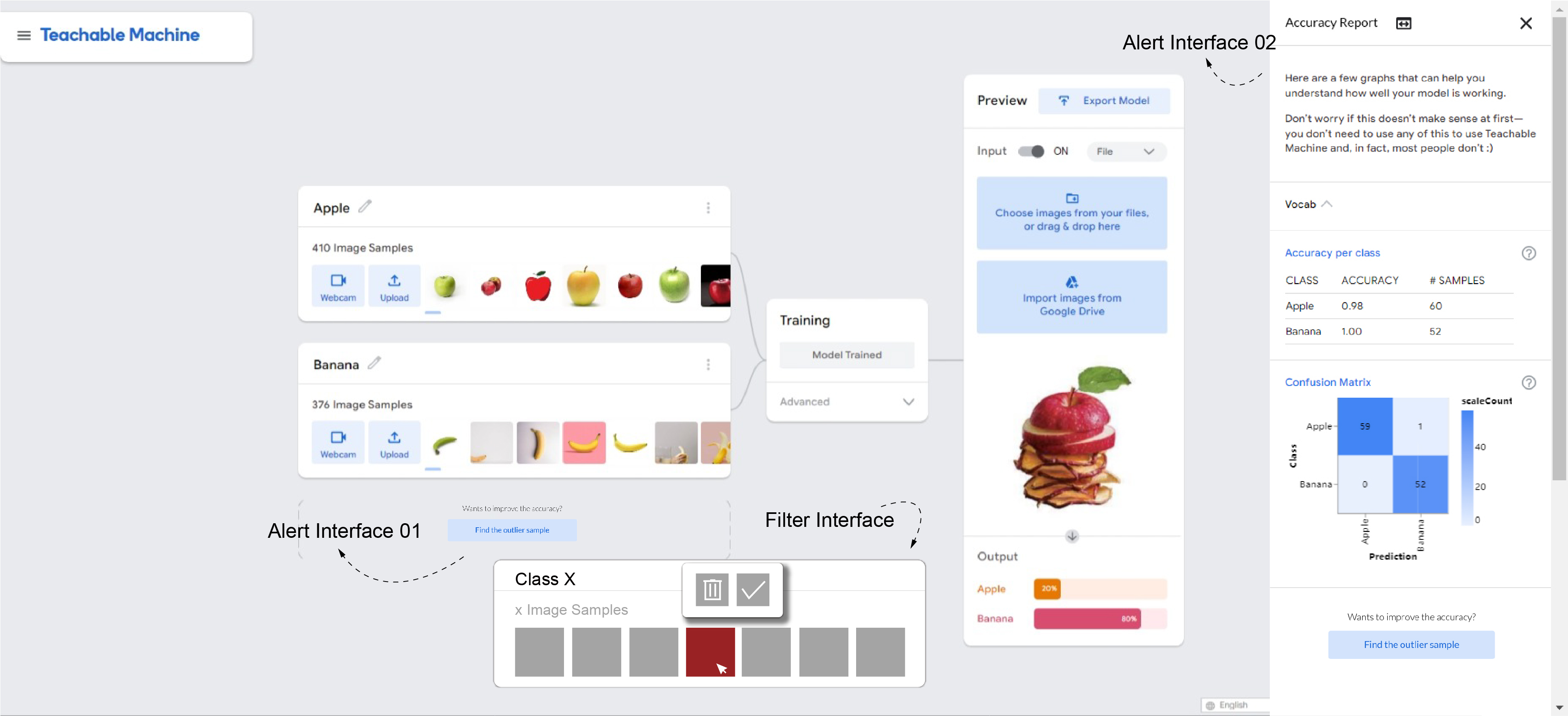
最终方案:“提醒”界面与“异常值过滤”界面
原型测试
我对 5 名参与者进行了测试:1 名计算机背景,2 名设计背景(建筑),2 名跨学科背景(人机交互与认知科学 / 管理)。大多数参与者具备基础的机器学习或统计知识。
第一轮:教程(对照组)
- 让参与者运行 TM,观察当前数据集在分类指定样本时的表现。
- 在两种提醒系统中选择偏好方案,作为后续异常值过滤界面的测试原型。
第二轮:使用人工过滤后的训练集训练新模型
- 参与者根据清单中建议的异常值,手动优化训练集。
- 在新的数据集上再次运行 TM,观察准确率变化,并结合异常值模式进行理解。
第三轮:将学到的异常值模式集应用于新模型
- 参与者基于第二轮学习到的异常值模式,对新的数据集进行人工过滤,再次运行 TM 并观察准确率变化。
- 进行测试后访谈与问卷调查。
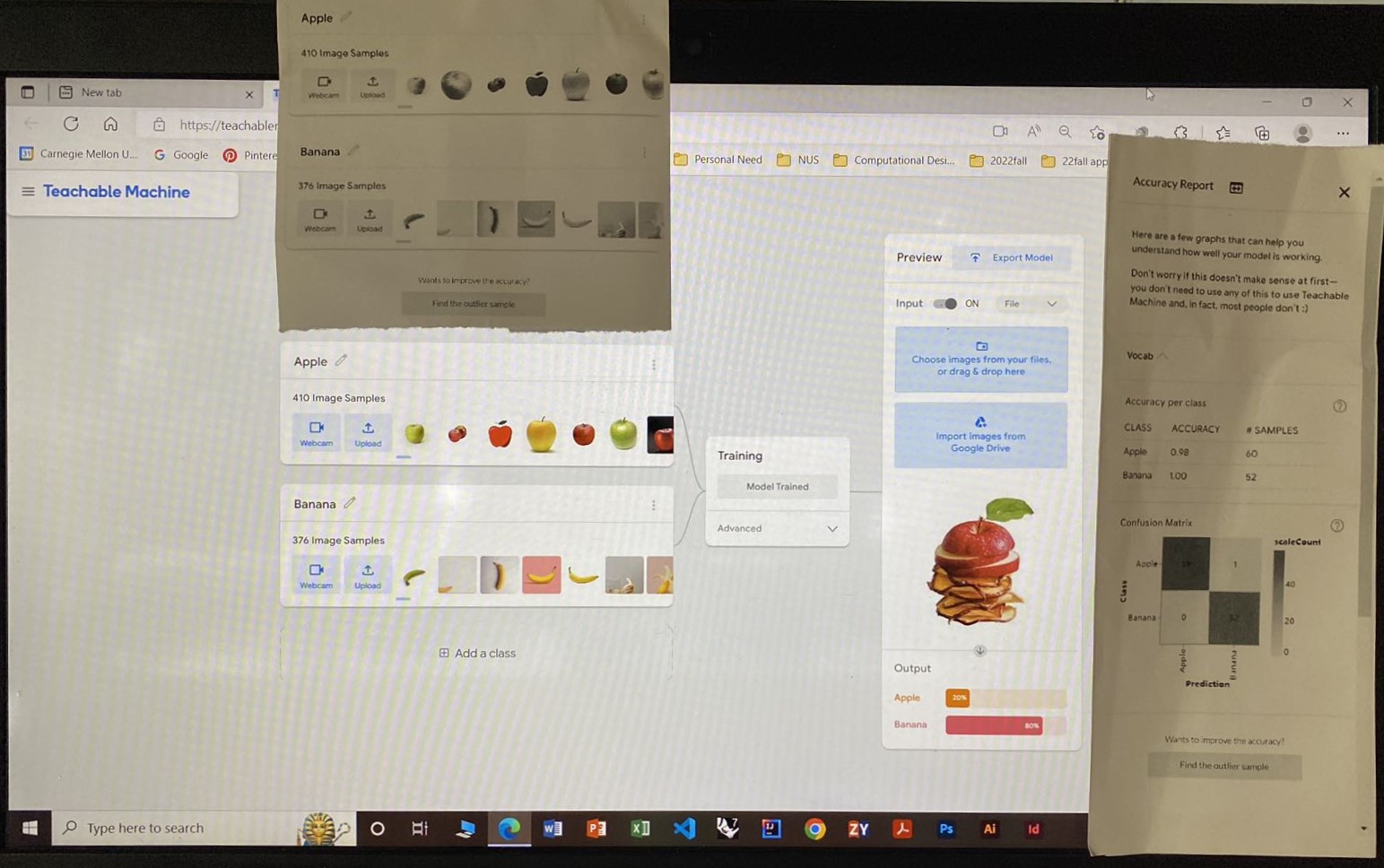
低保真纸质原型

异常值清单模板
定量分析
下图展示了 5 名参与者在三轮测试中样本预测准确率的变化。第二轮算法建议过滤(模型过滤)的准确率最高;与第一轮相比,经过第三轮人工过滤后的准确率显著提升,表明参与者可能从异常值提示功能中学习到了有效模式。
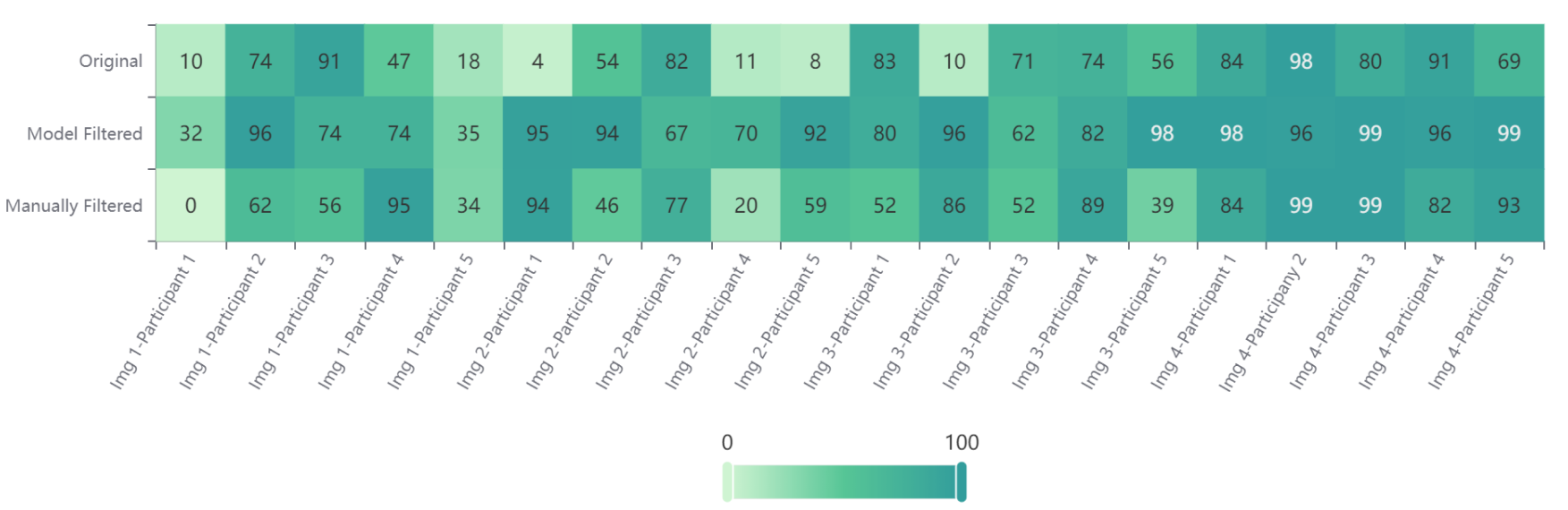
预测准确率结果
定性分析
原型测试后的问卷与访谈提供了预测准确率之外的洞察。参与者分享了他们的发现、感受与建议。
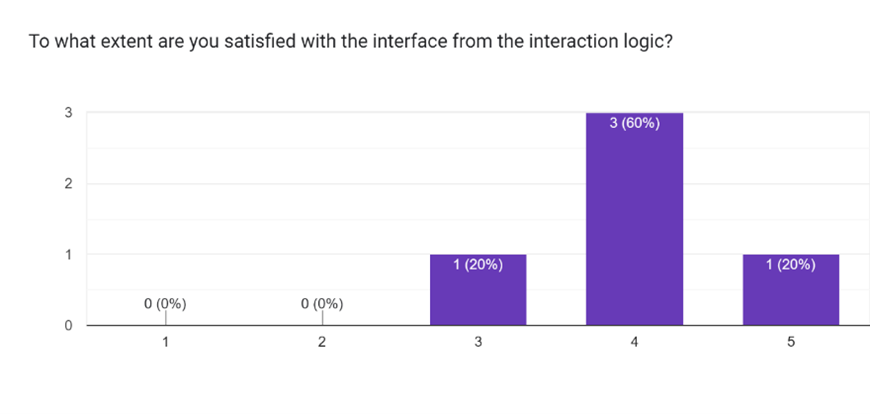
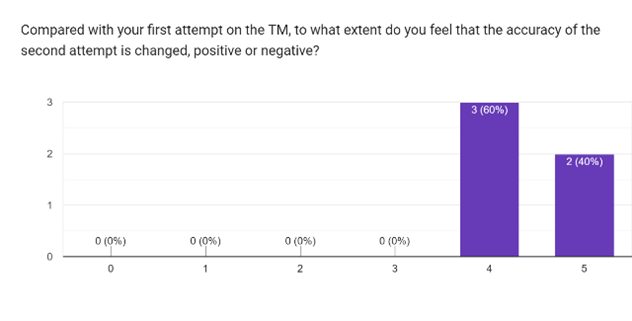
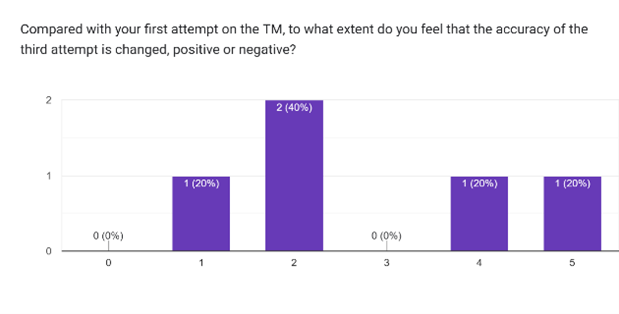
问卷结果
界面设计
- 提醒界面:参与者更偏好第二种方案,因为它展示了准确率,并帮助他们理解删除异常值的动机,同时激发进一步优化性能的思考。
- 异常值过滤界面:其良好表现被归因于简洁清晰的设计。
其他发现
参与者对 Teachable Machine 的内部机制表现出超出预期的好奇心。尽管愿意学习更多内容,他们仍倾向于与算法保持一定距离。第三轮的结果令具备专业背景的参与者感到失望,因为他们在第二轮中对自身判断更有信心。
洞察与未来工作
设计洞察
- “提醒”界面激发了用户学习理解预测性能影响因素的兴趣。
- “异常值过滤”界面为用户学习如何区分异常值及其对模型影响,提供了一种可行范式。
未来研究问题
参与者的反馈,尤其是其困惑之处,引出了若干值得进一步探讨的问题,包括:
- 为什么 Google 将“under the hood”机制放在高级功能中?
- 如何平衡人类偏见(用户选择)与模型偏见(算法偏见)?
- 该过滤系统在不可预测的新数据集上能否良好泛化?